Engineering
Next.js Session Management: Cookies, JWTs, and Server Sessions (2026)
March 27, 2026
Learn how UUIDv7, ULID, and Snowflake IDs work, how they differ, and when to use each for scalable, time-ordered, distributed systems.


Identifiers are a foundational element of software systems. Every database record, event, user, and transaction depends on an identifier to exist, be referenced, and move reliably across systems.
As systems scale and become distributed, traditional sequential IDs quickly show their limits. They introduce write contention, restrict scalability, and often expose internal system details. To avoid these issues, modern architectures rely on globally unique identifiers that can be generated independently.
Among these, time-sortable identifiers have become a practical default for distributed systems.
This article explains what time-sortable identifiers are, why they matter in distributed systems, and how UUIDv7, ULID, and Snowflake IDs compare from an architectural and operational perspective.
Identifier design directly affects system performance, reliability, and long-term operability. In distributed environments, identifiers must be generated across multiple services and regions without coordination, while maintaining global uniqueness and high write throughput.
Identifier structure also influences database indexing behavior, replication efficiency, and observability. Poor identifier choices often surface indirectly through fragmented indexes, degraded write performance, or difficulty reconstructing event flows during production incidents.
For these reasons, identifier selection should be treated as an architectural decision rather than an implementation detail.
Time-sortable identifiers embed time in a way that preserves chronological ordering when sorted. Records created later naturally follow earlier ones without requiring additional ordering logic. Compared to fully random identifiers, time-sortable IDs:
Importantly, these benefits are achieved without relying on centralized counters.
Before comparing specific identifier formats, it is useful to outline the requirements that modern systems typically impose on identifiers. These requirements arise from operational realities rather than theoretical design.
At a minimum, identifiers must be globally unique and locally generatable. They should support high throughput without introducing coordination overhead. Preserving time-based ordering is desirable to improve database performance and observability. Finally, identifiers should integrate cleanly with existing databases, APIs, and tooling, while avoiding unnecessary exposure of sensitive system details.
UUIDv7, ULID, and Snowflake IDs all aim to meet these requirements, but they do so through different design trade-offs.
ULID, short for Universally Unique Lexicographically Sortable Identifier, was introduced as an alternative to traditional UUIDs with improved ordering and readability. It combines a timestamp with random data and encodes the result as a fixed-length Base32 string.
A ULID is a 26-character Base32 string designed to sort correctly as a string.
The structure of a ULID places a millisecond-precision timestamp at the beginning of the identifier, followed by random bits to ensure uniqueness.
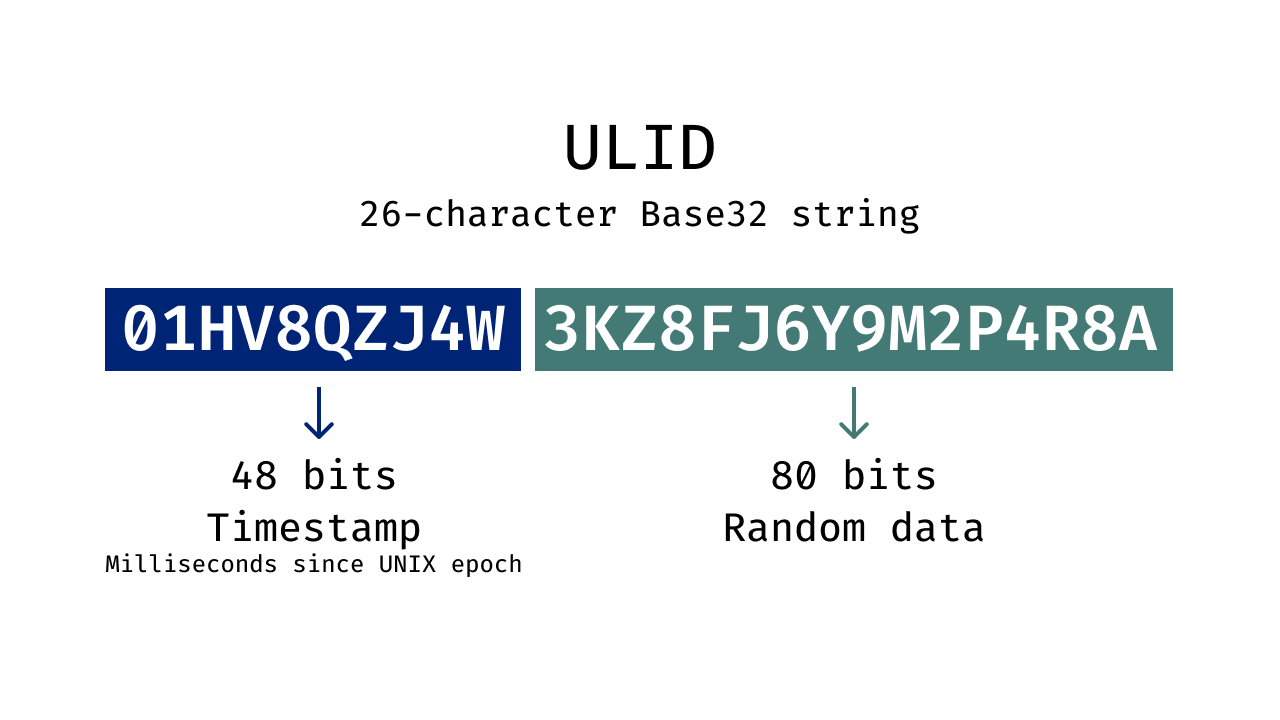
Because the timestamp comes first, ULIDs sort naturally using standard string ordering.
Limitation: ULIDs created in the same millisecond may not be strictly ordered unless a monotonic variant is used.
UUIDv7 represents a modern evolution of the UUID standard, designed to address the limitations of earlier versions. Traditional UUIDs either embedded hardware identifiers or relied entirely on randomness, both of which introduced challenges in contemporary distributed systems.
UUIDv7 is a 128-bit UUID that embeds time while remaining compatible with the UUID ecosystem.

When stored in binary form, UUIDv7 values increase over time, reducing index fragmentation compared to random UUIDs.
In practice, UUIDv7 timestamps can be generated and inspected using tools such as Authgear’s UUIDv7 Generator & Timestamp Extractor (RFC 9562).
Limitation: Ecosystem support is still evolving, though adoption is growing.
Snowflake-style identifiers take a more structured approach to identifier generation. Originally developed to support extremely high write throughput, they encode multiple pieces of information into a compact integer.
Snowflake IDs are 64-bit integers optimized for extremely high write throughput.
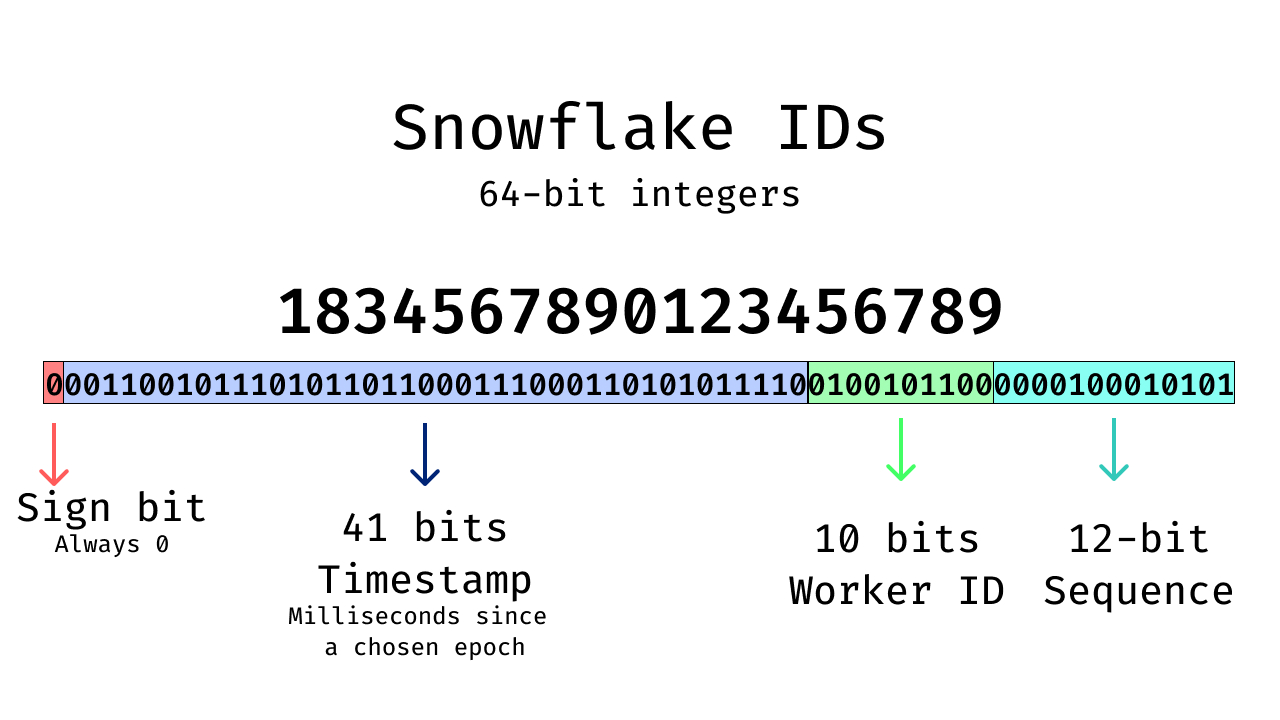
A common layout is:
This structure allows each node to generate thousands of IDs per millisecond while preserving strict ordering per node.
Limitations: Requires worker ID management and reliable clock synchronization.
Although UUIDv7, ULID, and Snowflake IDs all support time-based ordering, they prioritize different system characteristics.
The appropriate choice depends on system scale, performance requirements, and the level of infrastructure control available to the team.
Time-sortable identifiers keep inserts mostly sequential, reducing index fragmentation and improving cache locality. This leads to more predictable write performance as data grows.
They also improve observability by allowing engineers to infer creation order directly from identifiers, simplifying log correlation and incident debugging.
Here are some of the key observability and operational benefits of using time-sortable identifiers:
All time-sortable identifiers expose approximate creation time.
Identifiers exposed in APIs or URLs should be evaluated carefully based on privacy and threat models.
Selecting an identifier strategy is a foundational architectural decision that affects how a system scales, performs, and operates over time. While many systems begin with simple defaults, those choices can become difficult to reverse as data volume, traffic, and distribution increase. A careful evaluation early on helps avoid performance bottlenecks and operational complexity later.
When choosing between options such as UUIDv7, ULID, and Snowflake IDs, teams should assess both immediate requirements and long-term expectations. The following considerations can help guide that decision.
The current and expected scale of a system plays a major role in determining which identifier strategy is appropriate. Smaller systems with limited concurrency have more flexibility, while large or rapidly growing systems require identifiers that perform reliably under sustained write pressure.
In distributed architectures, identifiers must be generated independently across services and regions. Time-sortable identifiers are particularly well suited to these environments because they reduce database index fragmentation and maintain predictable write patterns as data grows.
Teams should also consider future growth, including increased throughput or geographic expansion, and ensure the chosen approach will continue to perform under those conditions.
Identifiers interact closely with databases, and their structure directly influences storage efficiency and query performance. Some databases handle ordered identifiers more efficiently than random ones, particularly in write-heavy workloads.
Teams should evaluate how identifiers will be stored and indexed, and whether they will be used for range queries or pagination. UUIDv7 offers improved write performance when stored in binary form while maintaining compatibility with existing UUID-based systems. ULID is well suited to environments that rely on string keys and lexicographic ordering. Snowflake IDs, as compact integers, deliver strong performance in databases optimized for numeric primary keys.
Understanding these trade-offs helps prevent performance issues that only emerge at scale.
Operational maturity should strongly influence identifier choice. Some identifier strategies introduce additional responsibilities that require ongoing management.
Snowflake-style identifiers, for example, depend on careful assignment of worker identifiers and consistent clock synchronization. These requirements can be manageable in tightly controlled environments but introduce risk in more dynamic or decentralized systems. Clock drift or configuration errors can directly affect identifier generation.
By contrast, UUIDv7 and ULID are fully decentralized and easier to operate. They avoid coordination requirements and reduce the likelihood of operational failures, making them attractive for teams seeking simplicity and resilience.
How and where identifiers are exposed is another important factor. Identifiers used internally carry different risks than those exposed through APIs, URLs, or client-facing systems.
Time-sortable identifiers reveal approximate creation times, which may be acceptable or undesirable depending on the context. Snowflake IDs can expose additional structural information about infrastructure or scale. UUIDv7 and ULID generally limit exposure to time information alone, making them a safer choice for many public-facing use cases. Teams should evaluate privacy requirements, regulatory obligations, and threat models when making this decision.
There is no one-size-fits-all identifier strategy. The right choice depends on system scale, database characteristics, operational capabilities, and security considerations. For many modern applications, UUIDv7 offers a balanced default with minimal operational overhead. ULID remains a strong option where readability and string-based sorting are important. Snowflake IDs are best suited for high-throughput systems with mature operational controls.
By treating identifier selection as a deliberate architectural decision, teams can adopt a strategy that supports long-term scalability, performance, and operational clarity.
Choosing the right identifier strategy is a critical part of building scalable, reliable systems. Time-sortable identifiers such as UUIDv7, ULID, and Snowflake IDs help improve database performance, simplify observability, and support distributed architectures as systems grow.
By understanding their trade-offs and aligning them with system scale, operational maturity, and security needs, teams can make identifier choices that hold up over time.
Modern platforms like Authgear support this approach with practical, developer-friendly tooling.
Authgear’s UUID v7 Generator & Timestamp Extractor (RFC 9562) makes it easy to generate time-ordered UUIDs and extract embedded timestamps, helping teams adopt UUIDv7 with confidence and clarity.
Explore the Authgear UUIDv7 tool to generate compliant identifiers, understand their structure, and build systems designed to scale efficiently from the start.
Privacy is important to us, so you have the option of disabling certain types of storage that may not be necessary for the basic functioning of the website. Blocking categories may impact your experience on the website.